Worum geht es?
Ein Service Mesh ist eine Infrastruktur-Schicht, die Lösungen für typische Herausforderungen, die in Microservice-Architekturen auftreten, bereitstellt.
Siehe auch: What is a service mesh?
💡 Dieses Dokument bezieht sich auf Service Meshes für Kubernetes.
Herausforderungen
- Verschlüsselte Inter-Service-Kommunikation
- Serivce-zu-Service-Authentifizierung
- Authorisierung von Inter-Service-Kommunikation
- Service Discovery
- Observability (Success Rates, Latenzen, Topologien)
- Resilience (Retries, Timeouts, Failover)
- Load Balancing
- Traffic Management (Routing, Splitting, Mirroring, Canary Deployments)
Ein Service Mesh ist eine ganzheitliche, zentrale Lösung für diese Herausforderungen. Er löst diese Probleme für die Services, ohne dass die Services etwas davon wissen.
Funktionsweise
Control Plane & Data Plane
Die am weitesten verbreiteten Service-Mesh-Implementierungen verfügen über eine ähnliche Architektur und sind in eine Control- und eine Data Plane unterteilt.

Quelle: The Service Mesh
Die Data Plane setzt sich aus einer großen Anzahl aus Proxy-Servern (häufig Envoy) zusammen, die "neben" jeder Service-Instanz sitzen. In der Data Plane spielt sich die eigentliche Inter-Service-Kommunikation ab.
In der Control Plane sitzen Komponenten, die für das Kontrollieren der Proxy-Server aus der Data Plane zuständig sind. Die Control Plane kennt alle Services und weiß, welche Services unter welchen Bedingungen miteinander kommunizieren dürfen.
Oft handelt es sich bei der Control Plane um einen einfachen Kubernetes-Namespaces mit verschiedenen Deployments.
Sidecar Proxies
Die Proxy-Server sitzen "neben" jeder Service-Instanz, indem sie vom Service Mesh automatisch in jeden Kubernetes-Pod injected werden. Es handelt sich um einen Sidecar Container innerhalb des Pods, weshalb diese Proxies auch als Sidecar Proxies bezeichnet werden.

Quelle: The Service Mesh
Ausgehende Anfragen eines Services werden noch innerhalb seines eigenen Pods vom Proxy abgefangen. Dieser Proxy baut dann per mTLS eine verschlüsselte Verbindung zum Proxy des Ziel-Services auf.
Bei der Kommunikation zwischen den Proxies werden die eigentlichen Service-Mesh-Features angewendet: Es wird geprüft, ob die Services überhaupt Kommunizieren dürfen und ob es sich beim Gegenüber tatsächlich um den gewünschten Service handelt. Zudem werden Retry- und Timeout-Policies berücksichtigt und Metriken gesammelt. Die dafür notwendigen Informationen erhalten die Proxies direkt von der Control Plane bzw. von ihrem lokalen Node-Agent.
Implikationen
Das oben vorgestellte Design bringt mehrere signifikante Implikationen mit sich.
- Die Infrastruktur wird um n Proxies erweitert, wobei n = Anzahl aller Serviceinstanzen.
- Jeder Proxy konsumiert zusätzliche CPU- und Memory-Ressourcen.
- Jeder Serviceaufruf wird um einen Proxy-Hop erweitert.
Warum sollte man diese zusätzlichen "Moving Parts" in Kauf nehmen?
💡 Alternativ zur Sidecar-Proxy-Architektur gibt es auch weniger invasive Lösungen wie beispielsweise Node Agents oder native Implementierungen oder Sidecar, die von einigen Service Meshes unterstützt oder sogar bevorzugt werden.
Vorteile
Unabhängig davon, welche Business-Logik die Services ausführen, ist der Traffix zwischen den Services eine ideale Stelle, um Networking-Features einzubauen.
Ein Service Mesh bringt gegenüber herkömmlichen Lösungen eine Reihe von Vorteilen:
- Alle Networking-Features werden an einer zentralen Stelle (Control Plane) verwaltet.
- Networking-, Resilience-, Observability- und Traffic-Management-Logik müssen nicht mehr in jedem Service einzeln implementiert werden.
- → Durch die Entkopplung vom Anwendungscode werden Services leichtgewichtiger und Entwickler können sich auf die Business-Logik konzentrieren.
- → Es ist günstiger, neue Services zu bauen.
- → Es handelt sich um eine einheitliche Lösung für alle Tech Stacks und Frameworks.
- Die Services wissen nichts vom Service Mesh, ihrem Sidecar-Proxy und den Netzwerk-Policies, denen sie unterliegen.
- → Service-Mesh-Einstellungen können sich unabhängig von den Services ändern.
- Das Ownership von Networking-Policies gelangt zurück zum Operations-Team.
- Manche Service Meshes können sich von mehreren Clustern aus zusammenschließen, um einen globalen Service Mesh zu bilden. Netzwerk-Policies können so konsistent über mehrere Plattformen und Regionen angewendet werden, z. B. On-Premise und AWS.
Implementierungen
Die nachfolgende Tabelle gibt einen kurzen Überblick über die bekanntesten Service-Mesh-Implementierungen. Auch wenn ein Cloud-Anbieter seinen eigenen Service Mesh anbietet, können dort natürlich auch die jeweils anderen Service Meshes deployed werden.
| Service Mesh | Hersteller/Initiator* | Open Source |
|---|---|---|
| Consul | HashiCorp | ✅ |
| Consul Enterprise | HashiCorp | ❌ |
| Linkerd | Buoyant | ✅ |
| Istio | ✅ | |
| Anthos | ❌ | |
| Kuma | Kong | ✅ |
| Kong Mesh (Kuma Enterprise) | Kong | ❌ |
| AWS App Mash | AWS | ❌ |
| Open Service Mesh | Microsoft | ✅ |
| Traefik Mesh | Traefik Labs | ✅ |
| Grey Matter | Grey Matter | ❌ |
** Initiator: Einige Service-Mesh-Projekte wurden von einer Firma gestartet und dann als Open-Source-Projekt verfügbar gemacht und an die CNCF gespendet.*
Verbreitung
Laut der CNCF Survey 2020 benutzen 27% der befragten Unternehmen einen Service Mesh in der Produktivumgebung (50% Anstieg gegenüber 2019) und 23% haben einen bereits Service Mesh im Einsatz, befinden sich aber noch in der Evaluationsphase. Weitere 19% planen, innerhalb der nächsten 12 Monate einen Service Mesh einzuführen.
Die am weitesten verbreiteten Service Meshes sind dabei Istio, Linkerd und Consul.
Quelle: CNCF Survey 2020 Report
Features
Security
Verschlüsselte Inter-Service-Kommunikation
Die meisten Service-Mesh-Implementierungen bieten eine Verschlüsselung der Inter-Service-Kommunikation via mutual TLS (mTLS). Vor allem von Consul wird dieses Feature als Teil eines Zero-Trust-Konzeptes stark vermarktet.
Consul stattet jeden Service mit einer eigenen Identität aus, das als TLS-Zertifikat hinterlegt wird. Bei ausgehenden Requests verifiziert der Client über die öffentliche Consul Certificate Authority das Zertifikat des Ziel-Services. Zudem stellt der Client sein Zertifikat dem Ziel-Service zur Verfügung. Nach einem erfolgreichen TLS-Handshake ist die Verbindung verschlüsselt.
Im Gegenzug verifiziert auch der Ziel-Service das Zertifikat des Clients über die CA. Danach wird geprüft, ob die erforderliche Authorisierung des Client-Services vorhanden ist (siehe Authorisierung von Inter-Service-Kommunikation).

Quelle: Secure Applications with Service Sidecar Proxies
Alle involvierten API-Requests erfolgen nicht direkt in die Control Plane, sondern gehen zum lokalen Consul Node Agent, der diese Daten in einem In-Memory-Cache hält. Damit nimmt jeder API-Call nur einige Mirkosekunden in Anspruch.
Service-zu-Service-Authentifizierung
Eine Verschlüsselung per mTLS erlaubt nicht nur eine sichere Kommunikation zwischen den Services, sondern auch ein identitätenbasiertes Arbeiten. Jeder Service authentifiziert sich mit seiner X.509-Identität bei anderen Services.
Das identitätsbasierte Arbeiten wiederrum ermöglicht die sichere Authorisierung von Inter-Service-Kommunikation.
Authorisierung von Inter-Service-Kommunikation
In einem Zero-Trust-Network dürfen Services standardmäßig nicht miteinander kommunizieren, sondern müssen explizit authorisiert werden, mit einem anderen Service zu sprechen.
Consul verwendet beispielsweise Intentions, um die Kommunikation zwischen zwei Services zu erlauben oder zu verbieten. Eine Intention kann über die Consul CLI, die UI oder deklarativ und versionierbar über ein Kubernetes-Manifest erstellt werden:
YAML:
apiVersion: consul.hashicorp.com/v1alpha1
kind: ServiceIntentions
metadata:
name: web-to-api
spec:
destination:
name: api
sources:
- name: web
action: allowDie Consul UI bietet einen globalen Überblick über alle Intentions.
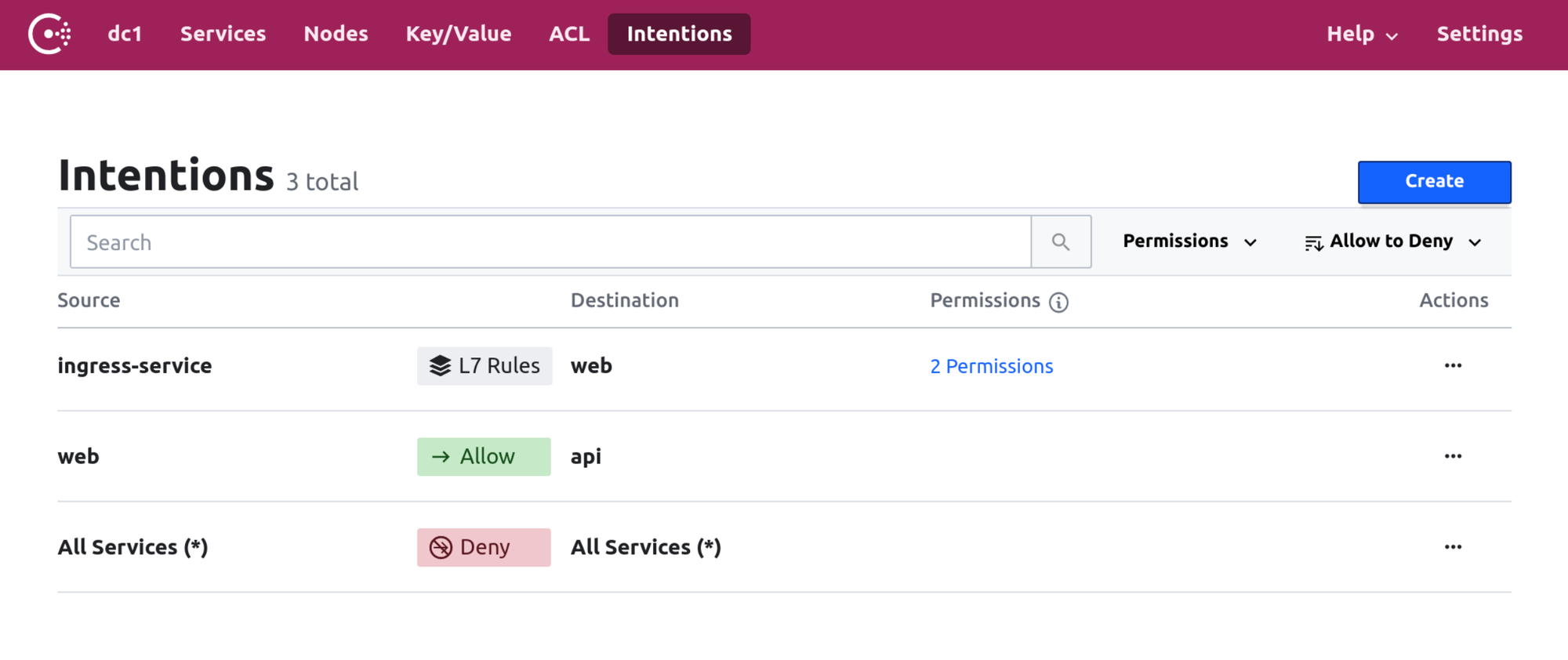
Quelle: Application Aware Intentions with Consul Service Mesh
Resilience
Retries und Timeouts
Retries und Timeouts sind ein elementarer Bestandteil in einer Microservice-Architektur. Häufig werden beide Werte, vor allem die Anzahl erlaubter Timeouts, manuell oder gar willkürlich festgelegt. Daraus ergeben sich zwei Probleme:
- Einerseits muss die Anzahl an erlaubten Retries so groß sein, dass der Client tatsächlich noch eine Chance hat, an die gewünschte Antwort zu kommen - und andererseits können zu viele Retries eine unnötig große, zusätzliche Last auf den Ziel-Service bringen.
- Die zusätzliche Last kann dazu führen, dass der Ziel-Service noch langsamer wird, was wiederum neue Retries zur Folge hat. Ein "Retry Storm" entsteht.
Viele Service Meshes bieten eine weitaus intelligentere und datengetriebenere Möglichkeit, die Anzahl der Retries zu steuern: Linkerd behält beispielsweise einen Überblick über das Verhältnis zwischen regulären Anfragen und Retries, und lässt nur so viele Retries zu, dass dieses Verhältnis unterhalb eines konfigurierbaren Limits bleibt.
Werden beispielsweise 25% als Limit konfiguriert, lässt Linkerd die Proxies nur so viele Retries ausführen, dass die reguläre Last auf den Ziel-Service nicht um mehr als 25% ansteigt.
Fault Injection
Um die Resilienz und Stabilität eines Systems im Fehlerfall zu prüfen, bieten manche Service Meshes Fault Injection als eine Form des Chaos Engineerings an. Dabei wird die Fehlerquote von Services künstlich erhöht.
Dadurch, dass sich die Inter-Service-Kommunikation in der Data Plane des Service Meshes abspielt, sind für die Fault Injection keine Änderungen im Code notwendig.
Traffic-Management
Routing
Service Meshes erlauben es, Traffic zwischen Services anhand von Layer-7-Kriterien wie beispielsweise HTTP-Methoden, Request-Headern oder Pfad-Präfixen zu routen. In der Regel handelt es sich bei einem Routing-Eintrag um ein Kubernetes-Manifest:
YAML:
apiVersion: consul.hashicorp.com/v1alpha1
kind: ServiceRouter
metadata:
name: web
spec:
routes:
- match:
http:
pathPrefix: /admin
destination:
service: adminSplitting und Canary Deployments
Nachdem der Traffic zu einem bestimmten Service geroutet wurde, kann er zusätzlich gesplittet werden. Der Traffic wird zwischen zwei oder mehr Service-Instanzen aufgeteilt: Die erste Anfrage gelangt zu Service-Instanz 1, die nächste Anfrage zu Service-Instanz 2.
Als Splitting-Kriterium kann beispielsweise eine Gewichtung herangezogen werden: 80% des Traffics geht zu Service-Instanz 1 und 20% zu Service-Instanz 2. Dieser Mechanismus ermöglicht Rollout-Strategien wie Canary oder Blue/Green Deployments.

Quelle: Traffic Splitting for Service Deployments
Als Routing-Ziele können beispielsweise die Versionen 1 und 2 eines Services konfiguriert werden, sodass dann 80% des Traffics an Version 1 und 20% an Version 2 gehen - automatisch, deklarativ und ohne, dass die Services etwas davon wissen.
Mit Consul kann zusätzlich festgelegt werden, welche Service-Instanzen, die die Kriterien beim Routing und Traffic Splitting erfüllen, tatsächlich als Ziel verwendet werden können. So kann beispielsweise die Auswahl an in Frage kommender Service-Instanzen auf ein bestimmtes Rechenzentrum oder andere Kriterien beschränkt werden.
💡 Canary Releases, A/B-Tests und Blue/Green Deployments können mit Tools wie Flagger, die auf einem Service Mesh aufbauen, automatisiert werden.
Mirroring
Traffic Splitting ebnet gleichzeitig den Weg für Traffic Mirroring: Traffic aus der Produktivumgebung kann zum Beispiel in eine Staging-Umgebung gespiegelt werden, um das Verhalten einer neuen Service-Version in der Staging-Umgebung zu testen.
Observability
Service-Metriken
Da die Inter-Service-Kommunikation in der Data Plane des Service Meshes stattfindet, kennt der Service Mesh das Verhalten der Services (nicht innerhalb der Services, sondern nach außen) sehr genau. Dementsprechend bietet es sich an, Metriken zu sammeln.
Viele Service Meshes sammeln die "goldenen Metriken" - Success Rates, Requests pro Sekunde und Latenzen - automatisch und stellen ein Dashboard für die Daten bereit. Wohin die Metriken gesendet und werden, ist von der Implementierung abhängig und kann konfiguriert werden.
Auch von APM-Tools wie Instana werden Services Meshes unterstützt, siehe z.B. den Instana Consul Agent.
Topologien
Dadurch, dass sich der Service Mesh über die gesamte Microservice-Infrastruktur erstreckt, kann auch die Topologie der Infrastruktur einfach erfasst und visualisiert werden. Hier am Beispiel von Consul:

Quelle: UI Visualization
Ein Vorteil ist, dass Consul nicht nur die Topologie, sondern auch die entsprechenden Intentions und Metriken zu den Services kennt. Die Dashboards sollen dabei nicht größere Monitoring-Tools ablösen, sondern einen schnellen Überblick verschaffen.
Hands-On
In der folgenden Demo wird Consul auf minikube zusammen mit zwei Test-Services deployed.
Requirements
Consul installieren
Um Consul im Cluster zu installieren, muss zunächst das Helm-Repository hinzugefügt werden:
Code:
helm repo add hashicorp https://helm.releases.hashicorp.comAnschließend müssen die Chart-Values in einer Datei values.yaml abgelegt werden.
YAML:
global:
name: consul
datacenter: dc1
server:
replicas: 1
securityContext:
runAsNonRoot: false
runAsGroup: 0
runAsUser: 0
fsGroup: 0
ui:
enabled: true
service:
type: "NodePort"
connectInject:
enabled: true
controller:
enabled: trueNun kann der Chart installiert werden.
Code:
helm install -f config.yaml consul hashicorp/consulConsul-UI testen
Die UI von Consul kann nun im Browser geöffnet werden:
Code:
minikube service consul-uiServices deployen
Nachfolgend werden zwei Services deployed: Ein Backend-Service namens counting, der bei jedem Aufruf eine Zahl hochzählt sowie ein Frontend-Service namens dashboard, der die Zahl vom Backend abfrägt und anzeigt.
Zunächst muss das Backend-Manifest als counting.yaml angelegt werden:
YAML:
apiVersion: v1
kind: ServiceAccount
metadata:
name: counting
---
apiVersion: v1
kind: Service
metadata:
name: counting
spec:
selector:
app: counting
ports:
- port: 9001
targetPort: 9001
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: counting
name: counting
spec:
replicas: 1
selector:
matchLabels:
app: counting
template:
metadata:
annotations:
"consul.hashicorp.com/connect-inject": "true"
labels:
app: counting
spec:
containers:
- name: counting
image: hashicorp/counting-service:0.0.2
ports:
- containerPort: 9001Analog dazu muss das Manifest für das Dashboard als dashboard.yaml gespeichert werden.
YAML:
apiVersion: v1
kind: ServiceAccount
metadata:
name: dashboard
---
apiVersion: v1
kind: Service
metadata:
name: dashboard
spec:
selector:
app: dashboard
ports:
- port: 9002
targetPort: 9002
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: dashboard
name: dashboard
spec:
replicas: 1
selector:
matchLabels:
app: dashboard
template:
metadata:
annotations:
"consul.hashicorp.com/connect-inject": "true"
"consul.hashicorp.com/connect-service-upstreams": "counting:9001"
labels:
app: dashboard
spec:
containers:
- name: dashboard
image: hashicorp/dashboard-service:0.0.4
ports:
- containerPort: 9002
env:
- name: COUNTING_SERVICE_URL
value: "<http://localhost:9001>"Nun können beide Services deployed werden.
Code:
kubectl apply -f counting.yaml
Code:
kubectl apply -f dashboard.yamlIn der Consul-UI tauchen nun beide Services auf und können dort inspiziert werden.
Das Dashboard aufrufen
Die Oberfläche des dashboard-Services kann mit einer Port-Weiterleitung unter localhost:9002 aufgerufen werden:
Code:
kubectl port-forward deploy/dashboard 9002:9002Inter-Service-Kommunikation verbieten
Um die Kommunikation zwischen dashboard und counter zu unterbinden, muss eine neue Intention angelegt werden - entweder über die Consul-UI, den CLI-Befehl oder ein eigenes Manifest (Consul bietet eine CRD hierfür).
Beispielsweise kann eine Intention als deny.yaml angelegt werden:
YAML:
apiVersion: consul.hashicorp.com/v1alpha1
kind: ServiceIntentions
metadata:
name: dashboard-to-counting
spec:
destination:
name: counting
sources:
- name: dashboard
action: deny
Code:
kubectl apply -f deny.yamlMit dieser Intention ist keine Kommunikation zwischen den beiden Services mehr möglich, was auch in der Consul-UI überprüft werden kann.
©️ 2021 Dominik Braun
